Marja-Riitta Koivunen, Dan Brickley, José Kahan, Eric Prud'Hommeaux, Ralph R. Swick
World Wide Web Consortium (W3C)
{marja,danbri,kahan,eric,swick}@w3.org
http://www.w3.org/
12 May 2000
We present a Web-based collaborative annotation system based on a general-purpose open metadata infrastructure where the annotations are modelled as a class of metadata. The annotations are viewed as statements made by an author about a Web resource. In the system we have implemented, annotations can be stored in one or more annotation servers on the Web. These servers make the annotation mechanism completely external to the annotated resource. The retrieval and presentation of annotations with the corresponding documents takes place in the client, for which we currently use the Amaya editor/browser. The annotation data itself is exchanged in RDF/XML form to provide other clients access to the annotation database. A general query language and a simple query interface via HTTP are provided to extract a variety of views of the annotation data.
This application is a step toward building an open RDF metadata repository infrastructure. To reach our goal we combine RDF with other Web technologies including HTTP, XML, and XPointer. The paper describes some of the issues we have faced and how we have solved them.
Keywords: Annotations, World Wide Web, RDF, Metadata
When you put together over 20 working groups and a supporting team developing standards for the Web you end up with all kinds of collaboration needs. The open mind and an adventurous attitude to "eat our own dog food" while testing W3C technologies in practice makes W3C a perfect environment to develop, explore and get feedback about different collaboration tools. We call this attitude "LEAD" for "live early adoption and demonstration".
Currently, most collaboration needs at W3C are fulfilled by open tools for Web publishing, e-mail discussion lists, irc, and issue tracking. There are some needs that don't yet have good support. For instance, is it quite laborious to attach and retrieve comments for different versions of the proposed standards. Other needs are related, for instance, to realtime updates of Web pages from electronic blackboards used in different sites or better integration between the viewpoints to different types of information.
A LEAD project for Web annotations was started to provide the missing support for annotation information while using suitable W3C technologies as much as possible. Annotations would give us an easy way for creating comments on a specific part of the document and for presenting the information in place while reading the document. In addition, we wanted to support other kinds of useful annotation practices. Some of us had prior experience with other annotation systems, not all of them Web based. To broaden our view of the users' needs concerning annotations, we started the project by informally interviewing about a dozen co-workers active in W3C working groups and developed several annotation scenarios based on that. Later, we also explored other Web-based annotation tools to see what we could learn from the different approaches.
The collaboration in a group is often very dynamic in nature. The concepts and vocabularies evolve as the groups start to understand the issues better or the participants change. We selected Resource Description Framework [RDF99, RDF00] as a general metadata technology for storing the annotations. RDF gives us flexible means to enrich the information when a working group comes up with new ideas. Furthermore, RDF offers means to explain the relationships between the annotations and the information created by the other collaboration tools in W3C. Finally, by using an open metadata infrastucture based on RDF we can easily support other annotation tools and technologies being developed for the semantic Web.
This paper concentrates on describing our motivations and the RDF infrastructure that we implemented to support the annotations. Section 2 examines previous annotation tools while Section 3 explains some user scenarios for annotations. The basic architecture of the annotations is illustrated in Section 4. The annotations and their corresponding RDF schema are explained in Section 5. Section 6 discusses the queries and Section 7 the protocols in more detail. Section 8 concludes the paper and presents our perspectives for future work.
This section discusses some previous annotation approaches. We concentrate on document-centered approaches where users are browsing documents and examining annotations related to them. There are also discussion-centered approaches to annotations, such as HyperNews [LaLiberte96]. In this case users browse discussion messages and threads and follow a link to a document that these messages annotate.
Annotations as a concept is nothing new. People have scribbled them in the margins of pages for ages. Annotations also appear in many text editors, where they can be embedded in the document itself. Even on the Web there are several annotation capable tools or servers, such as CritLink [Yee98] and ThirdVoice [ThirdVoice]. However, the tools are usually restricted or closed in one way or the other, because there are not yet standards to agree on some annotation practices. For instance, many implementations are inflexible or create barriers for non-technical users, such as demanding installation of plug-ins or providing technology driven user interfaces.
The two main categories to Web annotation systems are a proxy-based approach and a browser-based approach. In a proxy-based approach the annotations are stored and merged with a Web page by a proxy server and the browser user agent sees only the merged markup, typically with some semantic content removed. In a browser-based approach the browser is modified to merge the document and the annotation data just prior to presenting the content to the user. The annotation data is stored in the proxy or a separate annotation server. It is also possible to store annotations locally or provide site specific annotations, but these are less interesting to us because of their limitations. In the following, we have some examples of these tools.
The CritLink [Yee98] annotation tool uses the proxy approach where a Web page and its annotations are served through a different URI address than the original page. This approach works with any existing browser. However, the user must use different addresses for the document depending on which annotation proxy server is used. This is a limitation as we want to support the use of multiple servers each serving a certain community of users. The proxy approach inherently restricts also the types of content that can be annotated and the presentation styles that can be used for the annotations. Typically, presentation of the annotations is limited to the presentation styles available through HTML. InterNote [Vasudevan99] is a proxy based server that supports multiple annotation servers by modifying the browser.
Many of the annotation tools rely on specialized browsers to offer a better user interface. Already the version 1.2 of Mosaic browser [Mosaic93, Mosaic98] had a group annotation feature, which allowed members of a group to access annotations on a group annotation server. The annotations were shown as links at the end of the document. Unfortunately, deployment issues caused the central server to be taken offline. ComMentor [Röscheisen94] is another interesting browser-based tool developed for Mosaic that uses meta-information servers and supports several ways of presenting the annotations.
ThirdVoice [ThirdVoice] uses plugins to enchance web browsers so that they understand annotations. The users can annotate the page or some text on the page with discussions on selected topics. The discussions can be closed to a group of participants or open to anybody. Unfortunately, users cannot host their own servers. JotBot [Vasudevan99] is also a browser-based approach that uses Java applets to modify the browser behavior.
An interesting possibility for presenting the annotations on a Web page is to use internal DOM [DOM00] events without actually changing the mark-up of the page. Yawas [Denoue00] is an annotation tool that uses this approach. It codes the annotations into an extended URL format and uses local files similar to bookmark files to store and retrieve the annotations. A modified browser can transform the URL format into DOM events. The local annotation files can be sent to other users only by mail or copied by other means.
Xlink [XLink00], an XML linking technology currently under development in W3C, has some built in features in the mark-up for creating annotations. For instance, it is possible to store Xlink arcs in an external document that can be loaded with another document. The content defined by the end locator of an Xlink arc may be embedded to the location in a document defined by a starting locator of the arc. Using XLink provides the means to easily present the annotations in predefined ways in any browser implementing Xlink. However, using it directly in our our annotation model would unnecessarily complicate its structure.
Some Web sites offer annotation capabilities directly. The CAST web page tours [Grogan00] is an example of that. They provide an interesting user interface for specialized annotations for guided tours. The annotations about the page are shown in a column to the left of the page with a list of selected links that form the tour. User's can easily create their own tours, but they need to send them to a moderator to be added to the page.
From our perspective, approaches that modify the URIs of a resource are not flexible enough for our needs. Moreover, we want to annotate any page on the Web and share the annotations between users so tools that only store annotations locally are not sufficient. We want to have independent annotation servers similar to the ones in ComMentor, which can serve other metadata too and a general query language for the server. We also want a flexible user interface, that can dynamically support different annotation views. The most important aspect from our viewpoint is that the annotation model can easily evolve over time as the group and the changing concepts or categories it uses evolves. An open metadata infrastructure and utilization of W3C and other Web standards helps us in reaching that goal.
We interviewed users how they would like to use annotations and got many different answers. They were related to presenting the annotations, managing annotation overload, and using annotations in different ways, such as to rate pages. A basic requirement was also that we should be able to annotate any Web page. Based on these discussions, we developed a basic annotation scenario and then augmented it with different variations.
Selecting annotation servers
One of the basic requirements was that any group or an individual can host an annotation server. It may be dedicated for the needs of specific groups, companies or research areas. Therefore in all the scenarios, the user needs to define what annotation servers she wants to use. This is usually done by configuring the browser settings as the server definitions are probably quite stable for certain working contexts. The user interface can also provide functionality for more dynamic changes when needed, for instance, if the user works with many different groups from different organizations.
Basic annotation scenario
In the basic scenario, the user browses the Web documents as normally. When annotations are turned on the servers are queried to see if they hold any annotations for the document. If the annotation servers contain annotations related to the document, they or a subset of them are fetched and presented to the user according to her preferences. For instance, the user may prefer to see the annotations embedded in the document, presented on the side or bottom window or as "Post-It"™ notes, or present annotations by different authors with different highlightings or with their picture. The annotations may also be turned off so that they are not presented at all. The user can add a new annotation by simply selecting a place in a Web document and attaching an annotation to that. The annotation contains the actual content, and information about the annotation, such as the author and the creation time. The user may use these characteristics when filtering the annotations to examine only some of them at a time.
Rating annotations
Another common need was to be able to rate pages e.g. when the user sees a very good tutorial or an online book he can attach a rating annotation to that Web page. The rating annotation may be a free form comment e.g. "This page contains the best explanation of RDF schemas that I have seen so far." or a user or a user group can create their own scale, such as, "great, good, not worth looking" and use that as a rating. Rating annotations can be seen as a first step towards a direction of a more full blown collaborative filtering systems e.g. Firefly [Firefly] and its predecessor Ringo [Shardanand95]. However, in some cases this first step integrated with good query and search possibilities may well be enough for the users.
Annotating document versions
When an annotated document changes during the process we need to include annotation support for different document versions. For instance, the authors may copy annotations containing outstanding issues to new versions of the document. The browser needs to be able to show or replace annotations that become orphaned when the document changes or part of it is deleted. It would also help the user to know that the document content has changed after the annotation was made. The version problems that are hard to solve with technology can fortunately be often solved by applying social processes.
Annotations initiating discussions
Finally, annotations often relate to other collaboration tools. For instance, an annotation may lead to discussions. This could be supported by annotating the annotations themselves or using tools specifically targeted for discussions. We can also create a link from the first annotation to the archives of our mail-based discussion lists and use the thread support provided there to see the discussions. The discussion list tool could also provide a link back to the annotation that initiated the discussion. This would support the toggling between the document-oriented view and the discussion-list-oriented view.
Extendable annotations
It is important that the process of the group can evolve. Therefore the definition of an annotation needs to be extendable. For instance, when the group categorizes the Web pages or creates annotations it may select some annotation types; e.g. a comment, a correction-of-typo, or a hypothesis, at the beginning of the work. At some point the group may realize that it is wants to use other kinds of annotation types. Also, the annotations may be connected to other resources, such as, discussion threads or issues in an issue tracking system.
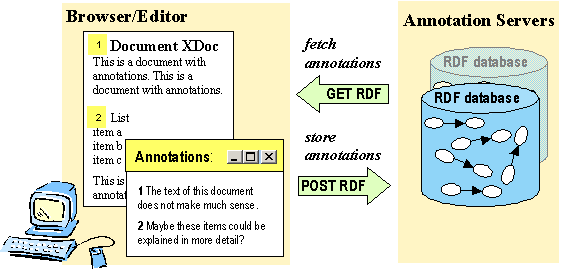
Our annotation tool consists of two main components: an annotation server that stores and serves the annotations in RDF/XML form and a browser/editor that provides users an interface for creating and reading the annotations. It corresponds to a browser-based approach, as defined in Section 2, that both understands and is capable of creating the annotations. When annotations are in use the server is consulted every time the user loads a new document and the annotations related to that document are retrieved and presented. The annotations can be presented in several ways according to the user preferences. Figure 4.1 illustrates two annotations marked with an enumerated icon in the XDoc document. It is possible to use several annotation servers by configuring them as default servers to the browser. Working groups, organizations and even individual users can easily host their own servers that support their specific needs.
Figure 4.1: The basic architecture of annotations.
The annotations that we handle are basically different kinds of statements about a document. They may be comments, typographical corrections, hypothesis or ratings, but there is always an author that makes a statement about the document or some part of it at a certain time. This is illustrated in Figure 4.2, where an author makes a statement about a document named XDoc. In this model the annotation consists of the actual content of the annotation in the user's statement bubble, the pointer to the annotated document, the person making the annotation, the time when the annotation was done, and other relevant information. The annotation schema is explained in more detail in Section 5. Pointing to a portion of an XML document is done by using the means of XPointer [XPointer99].

Figure 4.2: A basic annotation model with an author making a statement about a document.
The browser/editor communicates with the annotation server and presents the retrieved annotations to the user. In this development phase, Amaya is the primary browser/editor for the annotations. Amaya [Amaya] is Open Source software developed by W3C that supports HTML and a variety of XML markup schemas. Amaya is widely used by the W3C team for Web publishing. Later, our goal is that also other browsers would be able to at least read the annotation data. For instance, we have discussed the possibility of serving the annotations in a form usable with the CritLink tool [Yee98] or with Xlink knowledgeable browsers. To do that the server would need to convert the annotations from RDF to CritLink or XLink formats when that is requested as output. The generation of Xlink mark-up for presenting the annotations is pretty straightforward. We anticipate that a simple XSLT [XSLT99] transform can easily perform this task given the RDF/XML form as input.
Amaya provides the user an interface with several configuration options and different ways to view the annotations. We are experimenting with the user interface trying to support the basic scenarios described in Section 3.
The annotations are posted to the annotation server in RDF format and stored to an RDF database as general metadata triples (see Figure 5.1). When the annotations are queried the server converts the triples back to RDF syntax and sends them to Amaya. This RDF is interpreted by Amaya and presented to the users as annotations. We use a general query language syntax very similar to what is used in Algernon [Craw90] to query the RDF database. This is explained in more detail in Section 6. In addition, we use the existing HTTP POST and GET protocols [HTTP] to send and retrieve the RDF description of the annotations from the server. The protocol is explained in Section 7.
The most important feature of an annotation is that it supports the evolving needs of the collaborating groups. For instance, when the group advances in its work the group may want to change the types of annotations it uses. Also the group may add more relationships to other objects that relate to its work. RDF provides support for these needs e.g. by allowing the expression of new relationships, by allowing new annotation types and by supporting the transformations from one annotation type to another.
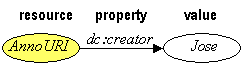
Figure 5.1. RDF triple format
RDF provides a simple yet very flexible framework for describing objects on the Web. At its most simple level, RDF provides (subject, property, value) triples (see Figure 5.1). A single triple is a statement that for the object whose Web address is subject, the given property has the specified value. The value may be a literal string or may be the address of another Web resource. Literal strings may contain XML markup. By design, RDF permits separate communities to develop independent metadata vocabularies and then freely mix statements using those vocabularies in a single database of triples. In RDF, the property names themselves have Web addresses and applications can use those Web addresses to make other statements about the meaning and use of each property and about its relationships to other properties.
The type of an annotation is defined by the user or the group by using different annotation classes. Such classes are a part of the RDF model. The general annotation super class is called an Annotation and we have defined a couple of sample subclasses based on it, such as, a comment, a deletion of some content, an addition of new content, a query or a warning. Figure 5.2 shows a list of these basic annotation classes defined in an annotation schema. New subclasses can be easily created. We can also easily add new properties to the annotation classes, for instance, we could add a property that defines an annotation set. This property can be queried with general RDF mechanisms and also presented as text. However, to do more advanced presentations with the basic RDF mechanisms we would need to develop presentation schemas for RDF.
Figure 5.2: Basic annotation classes.
Annotations are user made statements that consist of these main parts: the body of the annotation, which contains the textual or graphical content of the annotation, the link to the annotated document with a location within the document, an identification of the person making the annotation and additional metadata related to the annotation. By using RDF we can take advantage of other work on Web metadata vocabularies wherever possible. Specifically, we use the Dublin Core [DC99] element set to describe some of the properties of annotations. The annotation properties are illustrated in the RDF model presented in Figure 5.3 and the corresponding schema definitions for properties are defined in Figure 5.4.
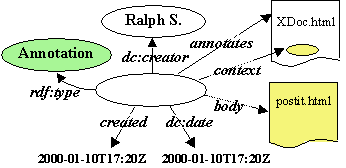
Figure 5.3: The RDF model of an annotation.
The RDF schema that defines the annotation properties consists of the property name and the natural language explanation. The type is one of the basic classes in Figure 5.2. or some other type of annotation defined elsewhere. The annotates property stores the link to the annotated document, body is a link to the content of the annotation, and dc:creator to the author making the annotation.
The context defines where exactly inside the document the annotation is attached to. We use XPointer [XPointer99] for defining the place within XML documents. It works well with static documents, but with documents that go through several changes, such as working group drafts, we may end up with orphan annotations or annotations pointing to wrong places. To prevent unnecessary loss of pointers we search for the nearest ID to a parent of the object use it as the starting point for the XPointer path. Fortunately, many documents usually have IDs at least at their main levels. Pointing to finer details after the ID will be done by other XPointer means, such as using text matching.
The additional annotation metadata includes date for the creation and last modified time, and related for adding relationships to other objects. Other metadata can be added to the annotation when the working group needs that. For instance, the working group will probably add their own properties directly and not specialize the related property.
Figure 5.4: The basic annotation properties.
Sample annotations utilizing this schema definition are presented in Section 7 while discussing the protocols.
Users want to filter the annotations they see depending on what they are doing. For example, in order to unclutter a heavily annotated document, a user may want only to display annotations made by certain users, or attached to a part of the document, or that were modified in the past 24 hours, or that correspond to a combination of these filters. The filtering may be done locally on the annotations that were already downloaded from the server or remotely, by means of the query string that will be sent to the server. Some of the server queries are going to happen frequently and they can be offered through an easy graphical interface. Other, more complicated queries can be offered to expert users or applications related to semantic Web that want to utilize the annotation information as part of their queries.
We have adapted a form of query language syntax very similar to what is used in Algernon [Craw90] because it was available to us from other prototyping work. This syntax uses triples in which place-holder variables are denoted by names beginning with a questionmark, such as ?a. The collect clause defines how to output the result of the query. For instance, the query in 6.1 returns all the annotations attached to a certain document with their annotation URL (?a), the context (?context), the creator (?creator), the time created (?created), the date (?date) and their annotation content URL (?body).
(ask
'((http://www.w3.org/1999/02/22-rdf-syntax-ns#type ?a
http://www.w3.org/1999/xx/annotation-ns#Annotation)
(http://www.w3.org/1999/xx/annotation-ns#annotates ?a
http://www.example.org/annotate/me)
(http://www.w3.org/1999/xx/annotation-ns#context ?a ?context)
(http://purl.org/dc/elements/1.0/creator ?a ?creator)
(http://www.w3.org/1999/xx/annotation-ns#created ?a ?created)
(http://purl.org/dc/elements/1.0/date ?a ?date)
(http://www.w3.org/1999/xx/annotation-ns#body ?a ?body)
) :collect '(?a ?context ?creator ?created ?date ?body))Figure 6.1: A sample query to the database from the annotation server.
The answer to the query is shown in Figure 6.2. It can consist of one or more annotation objects or return that no annotations were found. This RDF is processed by the browser and transferred to a format that is presented to the user.
<r:Description
about="http://quake.w3.org/CGI/annotate?annotation=/2000/05/08-18:04:55">
<r:type
resource="http://www.w3.org/1999/xx/annotation-ns#Annotation" />
<a:annotates
r:resource="http://www.example.org/annotate/me" />
<a:context>#P1</a:context>
<d:creator>John Smith</d:creator>
<a:created>Jan 1 1970</a:created>
<d:date>Jan 2 1970</d:date>
<a:body
r:resource="http://quake.w3.org/CGI/annotate?body=/2000/05/08-18:04:55" />
</r:Description>Figure 6.2: A sample answer to the query in Figure 6.1.
Currently, Amaya can only send the annotation server couple of different types of queries such as the one presented in Figure 6.3 asking for all the annotations related to a page at a given URL. In addition, as a first step to support a more general query mechanism users capable of doing so can write Algernon style queries to a text box in Amaya. In the future, we plan to extend the query language following closely the work on XML Query working group [QueryWG] and try to develop better user interfaces for the queries.
GET /CGI/annotate?w3c_annotation=http://www.example.org/annotate/meFigure 6.3: The client query to the server resulting in 6.1.
A design principle of the Web is that the Web address space is partitioned in a way to minimize the amount of central coordination required. We want annotation servers to be able to take advantage of a wide variety of database implementation schemes for storing and retrieving RDF statements and therefore we want the server to have minimal constraints on its use of its URI space to assign names to annotations. We also do not want clients to have to know an algorithm for constructing URIs for annotations that will be acceptable to a specific service.
We use the normal HTTP POST protocol for storing a new annotation to the annotation server and HTTP GET protocol for fetching the annotations and returning the result to the client. POST provides the necessary interface for the server to construct a URI for the new annotation and return that URI to the client. When the client has the URI for a previously created annotation, it can (with the proper permissions) use HTTP PUT to modify the annotation.
To create a new annotation, the client posts the RDF describing the annotation to a selected annotation server. Both the annotation and its body are anonymous RDF resources as the server is responsible for allocating the URIs for them. If the body already exists, as will happen if the annotation is another document that the user wants to use as an annotation, the URI can be specified in the RDF when the annotation is posted.
In Figure 7.1 we illustrate some RDF/XML that specifies an annotation of
the page whose URI is http://example.com/some/page.html. The
creator of this annotation is identified as "Ralph Swick". The text of the
annotation body is "This is an important concept."
POST /Annotation HTTP/1.1
Host: www.example.org
Content-Type: application/rdf
Content-Length: 623
<r:RDF xmlns:r="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:a="http://www.w3.org/1999/xx/annotation-ns#"
xmlns:d="http://purl.org/dc/elements/1.0/">
<r:Description>
<r:type resource="http://www.w3.org/1999/xx/annotation-ns#Annotation"/>
<r:type resource="http://www.w3.org/1999/xx/annotation-ns#Comment"/>
<a:annotates r:resource="http://example.com/some/page.html"/>
<a:context>#fragid</a:context>
<d:creator>Ralph Swick</d:creator>
<a:created>1999-10-14T12:10Z</a:created>
<d:date>1999-10-14T12:10Z</d:date>
<a:body>This is an important concept.</a:body>
</r:Description>
</r:RDF>Figure 7.1: Creating an annotation with POST method.
As specified by the RDF model, the data we pass to the server in the POST is a set of statements describing properties of the new (and unnamed) annotation resource that we would like the server to create. In response to the POST a new annotation is created and the following message is sent back. Now the server has created the URI's for the anonynomous resources and they can be used by the browser. The value of the a:body property is a URI of the content of the annotation; in this case the server implementation chose to store the text in a separate location and give it its own URI.
HTTP/1.1 201 Created
Location: http://www.example.org/Annotation/3ACF6D754
<r:RDF xmlns:r="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:a="http://www.w3.org/1999/xx/annotation-ns#"
xmlns:d="http://purl.org/dc/elements/1.0/">
<r:Description about="http://www.example.org/Annotation/3ACF6D754">
<a:annotates r:resource="http://example.com/some/page.html"/>
<a:body resource="http://www.example.org/Annotation/3ACF6D754text"/>
</r:Description>
</r:RDF>Figure 7.2: Response to the POST in Figure 7.1.
We did design around one issue with HTTP POST and GET in order to optimize performance when storing and retrieving simple annotations. Specifically, we want to be able to use HTML markup within an annotation body yet pass the body in a single HTTP message when creating and retrieving the annotation. In order to use HTML markup in the body, the correct architectural approach is to store the body as a separate resource with its own content type. We therefore designed a simple packaging protocol that permits both the client and server to specify embedded HTTP message bodies. To do this, we invented an RDF namespace for describing certain HTTP headers and we specify those HTTP headers as normal RDF properties:
<r:RDF xmlns:r="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:a="http://www.w3.org/1999/xx/annotation-ns#"
xmlns:http="http://www.w3.org/1999/xx/http#"
xmlns:d="http://purl.org/dc/elements/1.0/">
<r:Description>
<r:type resource="http://www.w3.org/1999/xx/annotation-ns#Annotation" />
<r:type resource="http://www.w3.org/1999/xx/annotation-ns#Comment" />
<a:annotates r:resource="http://example.com/some/page.html" />
<a:context>#fragid</a:context>
<d:creator>Marja</d:creator>
<a:created>2000-05-05T14:07:19Z</a:created>
<d:date>2000-05-05T14:07:44Z</d:date>
<a:body>
<r:Description>
<http:ContentType>text/html</http:ContentType>
<http:ContentLength>250</http:ContentLength>
<http:Body r:parseType="Literal">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Marja's Annotation</title>
</head>
<body>
<p>This is an <em>important</em> concept; see
<a href="http://example.com/other/page.html">other page</a>.</p>
</body>
</html>
</http:Body>
</r:Description>
</a:body>
</r:Description>
</r:RDF>Figure 7.3: Example annotation body using HTML.
With this little bit of ad hoc packaging we can have a POST method that explicitly creates two resources at the same message and a GET method that returns these same resources in one message. This packaging protocol has the additional advantage that it makes POST and GET of multiple resources an atomic operation; there is no window in which another client might modify the annotation body after the annotation properties have been returned but before the body is returned.
Currently we have the first version of the annotation server and the Amaya annotation user interface running. The tool utilizes a general purpose metadata infrastructure relying on RDF. It also uses HTTP, and parts of the XPointer standard. We can write external annotations, store them to the server as RDF, read them back as RDF, and present them in different ways within the document through the Amaya browser. Also we can make general Algernon style queries to select which annotations will be retrieved from the the annotation server.
Although our aim was to be as general as possible, we also left some generalizations to be finalized in the next versions of the annotation tool. These include the packaging of the different parts of the annotations in the protocol, a more general query language with a user interface to it, and a more general RDF parser for Amaya. The packaging work is related to W3C XML packaging work. Also the results of XML Query working group will help us in extending the query language. We have also been discussing the use of WebDAV protocol features [WebDAV] in our queries. Among other things, we want to investigate how WebDAV's property management mechanism can be integrated with RDF's model of first-class statements and properties.
Furthermore, we want to be able to better utilize the XPointer standard to get more accurate references to the annotated document. However, they will never solve all the problems as when we have external references we have no control of the changes in the internal structure of a document. Therefore, when the content of the annotated document changes part of the referencing will always be done by social means.
The next step will be to get feedback and improve the user interface. An important goal is also to make sure that the annotations we provide are accessible for disabled users. If designed right, the annotations can considerably help at least users with vision impairments. In addition, it will be interesting to experiment with modifications of the annotation schemas and the evolving annotation vocabularies as we will see in practice how much support we can get from RDF.
Still another future goal is to allow other browsers to at least read the annotations in our annotation servers. The Xlink standard provides a possibility to present the annotations with Xlink compatible browsers. The server can easily convert the RDF descriptions to Xlink form for these browsers when they become available. To support this and the creation of the annotations with other tools, we will need some standardization effort.
Many people at W3C have been participating in our informal collaboration meeting discussions at some point or contributing ideas to this work. We want to give special thanks to Tim Berners-Lee, Daniel LaLiberte, Charles McCathieNevile, and Johan Hjelm. Also Irčne Vatton and Vincent Quint from the Amaya team have given irreplaceable help to us. We also want to thank Mark Ackerman for his helpful comments and encouragement.
[Amaya] http://www.w3.org/Amaya/
[Craw90] James Crawford (1990). Access-Limited Logic: A Language for Knowledge Representation. Doctoral dissertation, Department of Computer Sciences, University of Texas at Austin, Austin, Texas. UT Artificial Intelligence TR AI90-141, October 1990.
[DC99] Dublin Core Metadata Element Set, Version 1.1: Reference Description, Dublin Core Metadata Initiative, 1999. http://purl.org/DC/documents/rec-dces-19990702.htm
[Denoue00] Laurent Denoue and Laurence Vignollet (2000). An annotation tool for Web browsers and its applications to information retrieval. In Proceedings of RIAO2000 (Paris,12-14 April 2000). http://www.univ-savoie.fr/labos/syscom/Laurent.Denoue/riao2000.doc
[DOM00] Lauren Wood et al. (eds.) (2000). Document Object Model (DOM) Level 2 Specification Version 1.0, W3C Candidate Recommendation 07 March, 2000. http://www.w3.org/TR/2000/CR-DOM-Level-2-20000307
[Firefly] http://hotwired.lycos.com/collections/virtual_communities/5.12_pattie_maes1.html
[Grogan00]David Grogan and Michael Cooper (2000). CAST's Model of Universal Design on the Web. In Proceedings of CSUN (Los Angeles, March 20-25, 2000). http://www.csun.edu/cod/conf2000/proceedings/0104Grogan.html. (See also http://dev.cast.org/castweb/tours/)
[Haugsjaa96] Erik Haugsjaa (1996). Collaborative Learning and Knowledge-Construction Through a Knowledge-Based WWW Authoring Tool. In Proceedings of WebNet96 (San Francisco, October 15-19, 1996), http://aace.virginia.edu/aace/conf/webnet/html/325.htm
[HTTP] R. Fielding et al. (eds.) (1999). Hypertext Transfer Protocol -- HTTP/1.1. June 1999. The Internet Society. http://www.ietf.org/rfc/rfc2616.txt
[LaLiberte96] Daniel LaLiberte, and Alan Braverman (1996). A Protocol for Scalable Group and Public Annotations. http://www.hypernews.org/~liberte/www/scalable-annotations.html
[Mosaic93] (1993) NCSA Mosaic Documentation: Group Annotations in NCSA Mosaic, http://www.ncsa.uiuc.edu/SDG/Software/Mosaic/Docs/group-annotations.html.
[Mosaic98] (1998) Mosaic Users's Guide:Annotations, http://www.ncsa.uiuc.edu/SDG/Software/Mosaic/Docs/help-on-annotate-win.html
[Röscheisen94] Martin Röscheisen, Christian Mogensen, and Terry Winograd (1994). Shared Web Annotations as a Platform for Third-Party Value-Added Information Providers: Architecture, Protocols, and Usage Examples. Technical Report STAN-CS-TR-97-1582, Stanford Integrated Digital Library Project, Computer Science Dept., Stanford University. November 1994, updated April 1995. http://www-diglib.stanford.edu/diglib/pub/reports/commentor.html
[QueryWG] http://www.w3.org/XML/Group/Query
[RDF99] Ora Lassila and Ralph Swick (eds.) (1999). Resource Description Framework (RDF) Model and Syntax Specification, W3C Recommendation 22 February 1999. http://www.w3.org/TR/1999/REC-rdf-syntax-19990222
[RDF00] Dan Brickley, and R.V. Guha (eds.) (2000). Resource Description Framework (RDF) Schema Specification 1.0. W3C Candidate Recommendation 27 March 2000. http://www.w3.org/TR/2000/CR-rdf-schema-20000327
[Shardanand95] Upendra Shardanand, and Pattie Maes (1995). Social information filtering: algorithms for automating "word of mouth". In Proceedings of the Conference on Human Factors in Computing Systems, CHI'95, (Denver, May 7-11, 1995), ACM. http://www.acm.org/sigchi/chi95/proceedings/papers/us_bdy.htm
[ThirdVoice] http://www.thirdvoice.com/
[WebDAV] http://www.ietf.org/rfc/rfc2518
[Xpointer99] Steve DeRose, Ron Daniel Jr., Eve Maler (eds.) (1999). XML Pointer Language (XPointer), W3C Working Draft 6 December 1999. http://www.w3.org/TR/1999/WD-xptr-19991206
[XLink00] Steve DeRose, Eve Maler, David Orchard, and Ben Trafford (eds.) (2000). XML Linking Language (XLink), W3C Working Draft 21-February-2000. http://www.w3.org/TR/2000/WD-xlink-20000221
[XSLT99] James Clark (ed.) (1999). XSL Transformations (XSLT), W3C Recommendation, 16 November 1999. http://www.w3.org/TR/1999/REC-xslt-19991116
[Vasudevan99] Venu Vasudevan and Mark Palmer (1999). On Web Annotations: Promises and Pittfalls of Current Web Infrastucture. In Proceedings of HICSS'99 (Maui, Hawaii, January 5-8, 1999). http://www.objs.com/survey/annotations-hicss.doc
[Yee98] Ka-Ping Yee (1998). CritLink: Better Hyperlinks for the WWW. Hypertext98 submission, April 1998, http://crit.org/http://crit.org/~ping/ht98.html
$Revision: 1.264 $ $Date: 2000/11/13 21:08:23 $