These are the minutes of the third annual W3C Technical Plenary held on 5 March 2003 at the Royal Sonesta Hotel in Cambridge, Massachusetts, USA. In addition to the day-long event, thirty W3C Working Groups and Interest Groups held face-to-face meetings over four days at the same location. The public plenary consisted of six sessions followed by an open "Tech Town Hall." This meeting record is transcribed from the IRC log and is not verbatim. Please send corrections to the W3C Communications Team.
The first annual W3C Technical Plenary took place on 28 February 2001 and the second on 27 February 2002.
Moderator: Dave Raggett (W3C/Canon). Panelists: Jim Larson (Intel), Scott McGlashan (PipeBeach), Debbie Dahl (Conversational Technologies), Janina Sajka (WAI Protocols and Formats WG), Roger Gimson (Hewlett-Packard)
Steven Pemberton (CWI/W3C): Isn't voice markup doing too much? Better to integrate into other languages, instead of trying to be free standing.
Scott McGlashan: Yes, next generation will do that, but for getting started doing a standalone solution was a good idea.
Rotan Hanrahan (MobileAware): In the early days, content creation was easy at the expense of access. Today we've got richer delivery, but creation is now much harder. Comments?
Jim Larson: Yes, it's more complex, but it's possible, and the complexity enables more exciting content. Authoring tools also are emerging which manange the complexity. We'll get good stuff, and also terrible stuff.
Tantek Çelik (Microsoft) in IRC: I agree that ease of authoring is still very important. Tools are good to have, but don't underestimate impact and necessity of hand-coders.
sj (?) endorses authoring tools need to take up the slack.
Gerald Edgar (Boeing): Size had changes, bandwidth has changed, but what about a radical shift, e.g. our punch presses could be Web clients. What kind of non-standard UI does this require.
Roger Gimson: For such a machine, the key aspect is a common way of expressing interaction. DI WG has been looking at XForms to provide a foundation for DI interaction.
Tantek Çelik: Authoring will be still be possible. It doesn't make sense to compare the past with the future, in the sense that the people can continue to author HTML as before, and it's why it's wonderful. We just reached a point where we address a lot more techniques and languages.
Roger Gimson: If filling in a field controls what the machine will do, separation of form from semantics is the key. Still more to do in the area of coping with the event aspects of this example.
??: Not just the user interaction, but the machine tool is physically creating the output presentation.
Roger Gimson: Yes, the output presentation is a bit of 3D stuff. Outputing to physical as opposed to electronic media is important to HP.
Martin Dürst (W3C): Different media have different challenges. Remind everyone that a lot of different [natural] languages out there, with many people speaking only one of them. Does progress in machine translation, perhaps not enough progress, point to an additional direction for your work? Multiple documents for multiple modalities in multiple languages increases the need to be good on re-use on other dimensions. Example -- voice interaction asks again if it gets the wrong answer, similar problem for wrong language, maybe?
Jim Larson: We have to work towards using one document for the different modalities, with different purposing.
Scott McGlashan: Spoken language identification isn't up to it yet. Multilingual recognition yes, 50-60 languages available at some level. Usual approach is generation from content on demand, to produce required language.
Jim Larson: Alternative, e.g. airline seat consoles, is non-linguistic interfaces.
Pat Hayes (IHMC, UWF): Advantages of speech, are advantages of natural language in general. If you're going to tackle NLU, that's a very hard problem.
Debbie Dahl: Yes, speech and language have similar advantages. In our groups, we're not trying to handle the full complexity of NLU. Focus on specifying the limited number of responses which are relevant, to constrain the recognition problem.
Jim Larson: We cheat a lot, we do word recognition, we write clever dialogues to guide people where we want to go.
Scott McGlashan: We're doing better now because of a shift from rule-based to statistics-based approaches, moving up from the low-level SR to NLU, forcing interpretation on any utterance.
Pat Hayes: Yes, I'm aware, but the significance of a 'not' can easily be lost.
Dave Raggett: Time to wind up.
Håkon Wium Lie (Opera): Thanks for good work. A further relevant spec., Media Queries, coming from CSS allows ss rules to be gated by result of queries to destination medium.
T. V. Raman (IBM): Back to question about authoring, yes, easy content creation is crucial. HTML started simple, got complex, then simpler with CSS. Going forward with multimodality and speech, we need to look for the same separation. Content authoring separated from mm interface on top.
[panel agrees]
Dave Raggett: Separation is very much on VB WG's agenda.
Ralph Swick (W3C): 3 MB bandwidth from here, okay if you stick to vanilla stuff. Please stop doing peer-to-peer file sharing or you risk getting cut off from net altogether.
Moderator: Steve Zilles (W3C). Panelists: Roy Fielding (Day Software), Tim Berners-Lee (W3C), Paul Cotton (Microsoft), Norm Walsh (Sun), David Orchard (BEA), Dan Connolly (W3C), Chris Lilley (W3C), Stuart Williams (Hewlett-Packard). [Only TAG person missing is Tim Bray.]
[Dan Connolly polls crowd. How many people subscribe to www-tag? A fair number. How many have skimmed the architecture document? A few.]
Roger Cutler (ChevronTexaco): With trepidation: (1) disingenuous that it's a misconception that the TAG is not telling WGs what to do. The TAG is telling WGs what to do. (2) If you read the arch doc, it's a more reasoned doc than many people's interpretation. Like what some people do to the Bible.
Dan Connolly: I think people share RC's concerns. I was nervous about the TAG initially. But W3C considered that it was better to try than not to try this experiment.
Steve Zilles: The TAG was set up to do some things that individual WGs can't do on their own. The other piece of the TAG charter was to prepare Rec track docs. "AC accountability."
Roger Cutler: In the WSA WG, someone expressed a strong opinion that a definition in the TAG's arch doc had to be used in the WSA document.
David Orchard (BEA): This is about the definition of the term "agent." The WSA WG was working on a definition of the term "agent"; the definitions were unrelated to one another. In their first cut, the WSA WG took the TAG's definition, changed it, and didn't reference the source.
Paul Grosso (Arbortext) in IRC: Personally, I have very little interest in rehashing this "political" stuff. I want to have time to talk about XML profiles and xml:id. Can we shorten this current rehashing.
David Orchard: I objected, stating that the WG should feed that info back to the TAG. Furthermore, I wanted a relationship such as "A Web Services agenda is a Web agent that..."
Steve Zilles: Would you consider the process to be working?
David Orchard (BEA): Yes, I think so.
Michael Champion (Software AG): What's the relationship between description and prescription in TAG activity? I see in the arch doc a lot of should's and must's. Not seeing the Web as it is from the should's and must's. Where do you draw the line between stupid cruft that people do and Web principles?
Chris Lilley (W3C): If people are doing something because they don't know better, we should improve outreach. If they do something because they have to, then we need to fix something.
Dan Connolly: I would like to see more argument behind principle in the document.
Chris Lilley: Also tension between brevity and rationale.
Noah Mendelsohn (IBM): I like what's in the arch doc, but it's not what I expected. I see instead a number of subtle insights. But perhaps also because architecture bases lie elsewhere; don't want to repeat. A specific example: "How much of the Web do you see to be REST-ful?" A good arch doc should give the big picture.
Tim Berners-Lee (W3C): Several different views of what "architecture" means. The TAG does something different from other WGs (e.g., WSA WG). Some people expect block diagram (with successive elaboration on request). I don't think we can put 4 corners around the Web. When people either extend the Web or bring something into the Web, what are the things they need to look out for? E.g., you can write as many new formats as you wish, but please use URIs.
Noah Mendelsohn: Then say what TBL said in the arch doc: Here's why you shouldn't look for a block diagram in this doc. Or change the title to something like "Principles for using the Web."
Chris Lilley in IRC: 'observations on we architecture'
Roy Fielding: A lot of what NM said is likely to be covered in as-yet-unwritten sections of the doc.
David Orchard: The TAG has been largely user-driven in their first year, responding to questions that have been raised. The Arch Doc is a resource where those findings can be pinned. In year 2 we expect to fill in other parts of the arch doc.
Ann Bassetti (Boeing, W3C AB): I'm relieved that the TAG was created; these questions used to come to the AB! The Advisory Board's discussion is calmer now that Paul Cotton is on the TAG ;) I strongly encourage those in this room to subscribe to www-tag.
[AB does her usual stellar job of reminding folks that "W3C is you!"]
Jonathan Robie (DataDirect Technologies): The TAG is doing a good job. I hear the TAG saying "There's a TAG finding; if it's broken; please tell us."
Ian Jacobs (W3C): Roger Cutler's suggestions on when-to-use-get are likely to result in a new revision.
Chris Lilley: Here's the technical meat. How many people would agree with the statement "ID's arise as the result of validation?" Can they arise through other means?
Jonathan Marsh (Microsoft): We get into the infoset....
Chris Lilley: Largely people assume that validation => fetching DTDs => IDs. Evidence of brokenness. In DOM 2, getElementByID. CSS2, ID selectors. XHTML 1.0, user agent conformance: "# When a user agent processes an XHTML document as generic XML, it shall only recognize attributes of type ID (i.e. the id attribute on most XHTML elements) as fragment identifiers." SOAP doesn't have a DTD at all (security and performance reasons). But it has ID.
Noah Mendelsohn: It's a schema ID, not a DTD ID.
Norm Walsh (Sun) in IRC: Gudge says (mail) SOAP IDs are neither DTD IDs nor XML Schema IDs.
[Chris hints that he is writing a finding as we speak on this topic.]
Chris Lilley: Lots of discussion on www-tag; people made good comments and suggestions.
Paul Grosso in IRC: The first sent of this slide is wrong.
Micah Dubinko (Cardiff) in IRC: xml:id -- just do it.
Al Gilman: We have an early draft of XML Accessibility Guidelines. These are guidelines for people building XML vocabularies. It sounds like this needs a defaulting rule. If you have an attribute called "id" it should either be of type ID or, if not, in the document the type should be indicated. Let simple processors do simple things. Provide info for smart processors to do more.
Chris Lilley (W3C): I would characterize that as the "sometimes steal 'id'" model.
Al Gilman: If you intend to use it for some other type, then you have to specify it inline; make the exception known.
Richard Tobin (University of Edinburgh): There's a common thread in several specs since XML - gradual removal of the internal subset and DTDs generally. There are three parts of DTDs handled in different ways: a) Content model and typing by xml schema, b) External entities -> XInclude, c) No current proposal for replacing character refs and internal entities. And yet! The question of IDs still arises. Why isn't the question of IDs covered by one of the three above technologies? I think IDs are more fundamental than the rest of typing. I think the xml:id or "steal id" proposals are the right ones. Take IDs out of typing.
Chris Lilley: IDREF also needs to be addressed, I would think.
Steven Pemberton: The TAG needs a rep from a mobile phone company - cost of downloading another resource. Good thing about small phones is they hurt less when someone you tell "download' to throws them at you. We need this solution in a Rec-track document.
Chris Lilley: TAG expects to summarize points that have been made, but not to do the work.
Steven Pemberton: Please get this done quickly.
Rigo Wenning (W3C): Relationship between ID and privacy. P3P WG struggled for a while over questions on type ID. Please stick to syntax of ID; if you try to get into semantics, you'll get lost.
Henry Thompson (University of Edinburgh): Yes, this is a problem and we should do something about it. I don't think the notion of subset is the right way to pursue it. The core value of XML is interoperability. The XML spec designed in two alternative conformance levels. I think the correct way to approach this problem is to introduce a third conformance level. You can conform and ignore the DOCTYPE statement. That way all xml processors will still be able to process all XML documents. E.g., SOAP Processor that conforms to this third class.
Chris Lilley in IRC: conformant processing of all content... with different results depending on validation or not... third conformance level with ignored doctypes
Roy Fielding: The need that I see in SOAP is the ability to tell a fully level compliant XML processor to disable those features. It's a different type of problem; not just standards compliance but providing developers with an option to do less.
Arnaud Le Hors (IBM): We discussed this issue yesterday in XML Core. I got an action to give a status report on our thoughts. We have been trying to not jump to any conclusions; we are going through the exercise of defining requirements first. I think the TAG's expression of its conclusion was misleading. I want to clarify that we are following the process of requirements, then proposing a solution. We also invite other WGs to tell us what their requirements are. The main incentive for doing work in this area is to avoid the proliferation of subsets. One proposal : XML 1.0 without DOCTYPEs. As a test, would this meet the needs of the XMLP WG if we toss doctype decl but not PIs?
Paul Cotton (Microsoft): I'm pleased that the WG where this work should be done is addressing this.
Dan Connolly: The TAG also looked at requirements.
Chris Lilley in IRC: or a conformance level that says ignore doctypes and ignore pis - wait, ignoring pis is the current situation .....
Michael Sperberg-McQueen (W3C): I'm glad that Core is looking at this. It's useful to learn from experience. We can learn from XML 1.0 experience. Failure of community to take up stand-alone solution. We would not, e.g., have the problem today that implementations assume that the DOCTYPE declaration is an instruction to the processor to validate. It's a declarative statement, not imperative. If implementers don't provide an option to turn it off, we will always have the problem RF cites. We already have three conformance levels in practice (1) validating (2) non-validating but DTD-aware and (3) non-validating and DTD-unaware. Whatever we do, the solution probably needs to incorporate a replacement for one important function - binding an instance to a particular document type definition. Maybe a solution is another magic attribute (a la schema location). Need to solve nesting problem.
David Cleary (Progress Software): Is the TAG considering deprecating the use of URNs for namespace documents?
[Point made about using URNs when you don't want the URI dereferenced.]
Dan Connolly: We decided that resources SHOULD have representations available.
[Paul Cotton polls crowd. How many people have read the minimal RDDL proposal? A few people.]
Tim Berners-Lee: You should not use URNs since you SHOULD make available a representation. One reason why this issue has been difficult to resolve - some of the people doing DAML, OWL, etc. are different from folks doing XML processing. Sem Web processors can resolve queries by picking up machine-readable defns of terms in real time. Getting info about terms is useful. In RDF, all the metadata can be in the RDF doc itself. The need for pointers to different types of resources (e.g., schemas) isn't as great in the sem web application. It's not obvious whether the TAG should be trying to make everyone use the same thing; solution might be to fill a couple of particularly large gaps.
Roy Fielding: You can use a URI that has a dereference mechanism already, or use a URI for which you are going to deploy the dereference mechanism yourself.
Steve Zilles: Have you written reqs for what a namespace doc should do?
David Orchard: Yes, 14 requirements are in discussion.
Steve Zilles: Many thanks to the TAG and to the audience for asking questions.
Moderator: Patrick Ion (Mathematical Reviews). Panelists: Stephen Buswell (Stilo), David Carlisle (NAG), Mikko Honkala (Helsinki University Of Technology), Steven Pemberton (CWI/W3C), David Landwehr (Novell)
Eric Miller (W3C) in IRC: What browser is being used in this presentation?
Ivan Herman (W3C) in IRC: This is not a browser, it is Novell's standalone XForms processor. Shows the dependencies among field appearances. Done purely using the dependencies based on the xpath values, no scripting.
Micah Dubinko in IRC: Details here.
Steven Pemberton: Important point is that when you make a submit, you do not replace the whole document.
Ivan Herman describes demo in IRC: SMIL document with SVG. It is a research browser at HUT, ongoing work. Completely open source in Java. Main principles: standards compliance, mixing XML docs, support XML+ns, XSLT, XHTML Basic + CSS, XSL FO. As a research project is to implement the latest of W3C; concentrating a lot on XForms, e.g. a bookmark editor (using list massaging in XForms). Mikko Honkala shows a SMIL + XForms demo to launch audio messages (submission errors are reported by voice)using unwritable four letter words.... SVG+XForms demo: map of Finland with user interface in XForms. Media Queries weather demo : for desktop, it shows as a 3D graph (using X3D), for phone, the outlook is just a small screen with data. The GUI is actually a SMIL document. Looking at a digital TV, there is again another SMIL document.
[applause]
Dan Connolly in IRC: hmm... TAG issue on mixed namespace docs... I wonder if these xsmiles folks have some advice.
Ivan Herman describes demo in IRC: Shows an XHTML doc with MathML inside. Two halves: presentation markup and content markup, shown on the example rendered in Mozilla; Mozilla has native MathML presentation. Client side XSL transforms content markup into presentation markup. Same document in IE, looks the same, Uses behaviors, and uses math player for design science. The same stylesheet transforms to HTML plus the necessary extension mechanism. Shows the XHTML source with a stylesheet at the top. In MathML I can use links, shows a link to Maple. Shows in presentation markup the formula is copy pasted to Maple, the copy paste is in MathML. It could be a mathematical service, the point is that this is not an image.
Max Froumentin (W3C) in IRC: Works in Mozilla and IE! (and Amaya) You can copy and paste the formulas from your browser, and send them directly to your computer algebra system.
Daniel Austin (W. W. Grainger): What strikes me is the commonalities of the problems, how do we make documents from multiple namespaces. Has W3C the intention to solve this problem once and for all, rather than in pieces?
Stephen Buswell: Is probably a problem for the TAG.
Dan Connolly: You guys know more of this than the TAG does. The TAG had the issue of mixing namespaces, so there is the work done in the mean time, it is good that part of this work is done. Do you see a solution from your perspective?
Stephen Buswell: I believe it is doable, I do not have a clear picture.
Philipp Hoschka (W3C): To respond to Daniel Austin's question, there was a task force to look at that issue, right now there is a new interest for that, Philippe Le Hégaret is looking for people working on this. If you are interested in that talk to him or to me; there is a chance that we will address the issue.
Ralph Swick in IRC: Component Extension Framework
Max Froumentin in IRC: Component Extensions (aka Plug-in API). There is a requirements document.
Steve Zilles: There is now more consciousness of what the problems really are.
Dan Connolly in IRC: TAG issue on mixed namespace docs, which got exploded into 3 smaller bits...
T. V. Raman: There is also a set of fundamental XML-ish format, like what Steven mentioned... The id problem... these are purely syntax, can be solved independently.
Chris Lilley: Responding to Daniel's point, the problem is when people create part of document, not the whole thing.
Dan Connolly in IRC: hmm... interesting point about "those bits can only go in once, so can't be used in XForms". "self-similar syntax" really does have teeth.
Ann Bassetti: One of the problems, why is it all these wonderful work has not been implemented at large. We need these things in products. It takes a loooong time to get it into products.
Tim Berners-Lee: The same thing that applies to MathML in SVG is the same when you encrypt something which you XSLT and you put in something else. Should we do the XInclude processing, then the encryption, does this mess up something? The model must be a top down one, elaborating top down... Don't think in terms of defining a document, rather define elements. You wont be able to change the meaning of your cousin elements. You asked whether W3C would solve it: you are W3C.
Richard Tobin: MIME to documents, some people said as it was the same as multi-namespace document. Different people want to define their own document. The solution the entity is not to tie to the namespace, it is not a one-to-one correspondence. Secondly: Tim describes a top down processing model. There are lots of different things one can do with the same document, I want to separate the processing of the document from the document itself.
Dan Connolly: The future is longer than the past. Lots of times Working Groups do sometimes first something which is fast but broken. Keep good the fight, the future is longer than the past.
Moderator: Wendy Chisholm (W3C). Panelists: Lofton Henderson (CGMO), Norm Walsh (Sun), Hugo Haas (W3C), Olivier Thereaux (W3C)
Dan Connolly in IRC: hmm... I much prefer glossaries that refer to the discussion of the term in context; i.e. more of an index.
Jos De Roo (Agfa-Gevaert N.V.) in IRC: DanC, any example?
Dan Connolly in IRC: stay tuned... to what/where?
Dominique Hazaël-Massieux (W3C) in IRC: The glossary project page linked from the slides.
Dan Connolly in IRC: seems to be in weblog form... is an RSS feed available?
Charles McCathieNevile (SIDAR/W3C): Are you looking at going over existing specs? That's what we are doing for translations of terms.
Olivier Théreaux: The ultimate goal is that we provide tools. Not just a single glossary.
Roger Cutler: I've been helping Hugo Haas on the Web services glossary. I disagree that a glossary architecture with levels will scale. You keep using "agent" as an example - that is a case that will work. Many other terms won't work. If you use terms with a different mindset you are screwed.
Dan Connolly in IRC: more glossary fodder
Wendy Chisholm: We are not limiting the number of definitions.
Arnaud Le Hors: I'm puzzled how the W3C staff addresses issues. Some of these things are in XML form, clearly marked. Don't ignore the XML that is already there.
Olivier Théreaux: I focused on HTML because it is hard to extract. Some people don't want to use XML Spec. Tools must be flexible.
Arnaud Le Hors: You should lobby more people to use XML Spec.
Martin Dürst: Some terms in XML Spec are not marked up.
Norm Walsh: People can use bad markup anywhere.
Tantek Çelik: <term> and <termdef> are new, why aren't we using <dl> <dd> <dt>?
Norm Walsh: XML Spec has more precise semantics.
RylaDog in IRC: and <dfn>
Paul Grosso in IRC: I think the english word "term" predates HTML.
Dan Connolly in IRC: (go TC! that was my question to spec-prod years ago. or to SGML-ERB or something. yes, seems gratuitous to me too.)
Olivier Théreaux: I read HTML 4.01 - it's less than clear. It isn't pushy about this. Freedom in use of <dl>.
Paul Grosso in IRC: I thought XML was extensible--why can't someone develop a DTD that uses terms in their own language like English instead of html-eze!
libby in IRC: so, as a little experiment, would anyone like to try this little rdf toy?
Moderator: Stuart Williams (Hewlett-Packard Labs). Panelists: Steven Pemberton (CWI/W3C), Roy T. Fielding (Day Software), Noah Mendelsohn (IBM), Brian McBride (Hewlett-Packard)
PStickler in IRC: Question for panel: Is a description of a resource a representation of that resource?
Micah Dubinko in IRC: No sweat for the computer, but what about the user?
Simon Hernandez (W3C) in IRC: Why not leave to authoring tools? vi rules!
Dan Connolly in IRC: If you count heads, I'm pretty sure, to several orders of magnitude, all authors use frontpage.
Dan Connolly in IRC: "The only time you hear about HTTP is when something goes wrong." -- RoyF
Roy Fielding: Multiple organizational boundaries. Distributed hypermedia system. Good for large data transfers. We need to plan for gradual fragmented change. It doesn't change that much, like HTML. Sensitive to user-perceived latency. Capable of disconnected operation. REST Architectural style is an attempt to come up with a rationale for showing/telling folks how their software sucks. What is it you are trying to achieve with your product on the web? REST Architectural style is the basis for how Roy designed HTTP 1.1 extensions, and for defense of them. Client-sever paradigm. Representational State Transfer (REST). REST Process View graph. REST Uniform interface. Pictures are not sufficient. Five primary interface constraints. How many webs should there be?
Noah Mendelsohn: At core we have a web of names named by a URI. In this, there is a web of widely deployed schemes. De facto, it is a web of things you can manipulate. Roy has given us a model: RESTful web. http/https are protocols of REST. Core protocols of web as deployed. Also web of widely deployed media types.
Dan Connolly in IRC: cool picture. Ian, this would be a great "story" for the arch doc intro, no?
Ian Jacobs in IRC: I'll check it out with Noah.
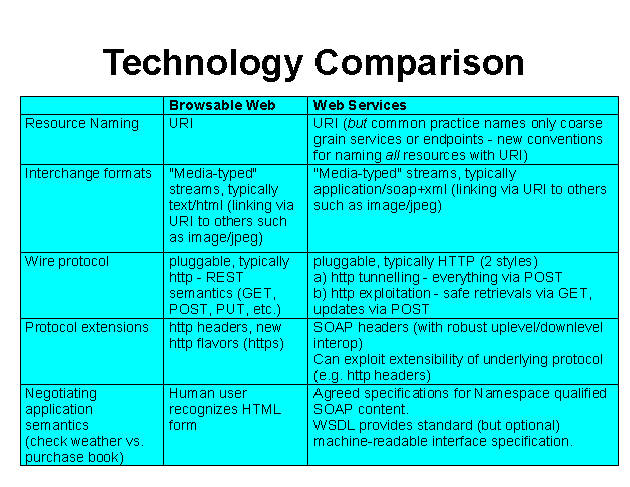
Noah Mendelsohn: Technology comparison. On browseable web, things are uris. Folks don't use uris aggressively enough. For example, you don't see uris for every stock quote. Web services need to run over more than http. Furthermore, history that SOAP has misused HTTP. The option is now there [in SOAP 1.2] to do things correctly, You cannot rely on people to know if they got the right thing.
Tantek Çelik in IRC: amazing. is there an HTML version of this presentation where the text is in markup instead of being trapped in a .gif?
Simon Hernandez in IRC: not that i am aware of :^(
Janet Daly (W3C) in IRC: hi, tantek. slides currently are in this format - generated from Freehand
Tim Berners-Lee in IRC: specifically that was mostly this slide.
Brian McBride: How many webs? ONE - but it is multifaceted and its architecture has structure. What does sWeb need from web architecture? naming, retrievability, precision, structure. Naming - sWeb needs to name things other than web resources with some precision - e.g. a car and a picture of a car are not the same thing. Retrievability - sWeb needs to be able to retrieve information associated with a name e.g. RDF Vocabulary definitions, OWL ontologies. [discussion of example]. One of my versions of hell is software generating last call comments.
Dan Connolly in IRC: hmm... no # in the URI of the 'non document' issues list. ah... there is a # in the 2nd option on this slide.
Tim Berners-Lee in IRC: In fact the web server doesn't say "that is not a document, look at Overview", it just returns the contents of Overview, n'est-ce pas?
Dominique Hazaël-Massieux in IRC: It doesn't, but that's a bug in Apache. It should set the content-location: header to Overview.html (which is not exactly saying "this is not a document" either, but closer).
Brian McBride: sWeb is building formal models - needs firm foundations to build on [[A resource can be anything that has identity.]] [[More precisely, a resource R is a temporally varying membership function M R (t), which for time t maps to a set of entities, or values, which are equivalent.]] from Roy's thesis.
Jonathan Robie: There are some things that are obviously core, or you don't have a web. You can argue how many you can squeeze in. Each of you has shown what a web is, while leaving something out that was essential to someone else. It is possible for many of us to spend a good part of our careers working on something that someone else has solved using a different method. I think instead of arguing who gets to be in the middle, we have to assume different folks use different tools.
Patrick Stickler (Nokia): Is a desrciption of a resource a valid description of the resource?
Roy Fielding: If you have a description of a resource that is the resource, then the resource is a description of a resource. There are huge discussions on www-tag. Folks assume there is a framework that is consistent. If you have a picture of a car then of course people would consider that different from the car.
Tim Berners-Lee in IRC: AV, please cut Roy's mike ;-)
Alan Kotok (W3C) in IRC: Technical description of discussion: Resources are cars.
Micah Dubinko in IRC: as are descriptions of discussions :-)
Jacek Kopecky (Systinet): Are Web services part of the WWW, or is the WWW part of the Web services world, or an application thereof? How about implementing HTTP over SOAP and calling it SHTTP?
RylaDog in IRC: xhttp
Noah Mendelsohn: We engineered SOAP to be more RESTful... The fact that our envelopes use URIs gives us better use (?) of them.
Roy Fielding: Most of his criticisms over the years were of SOAP 1.1.
Pat Hayes: There are no names on the web at all. Just links. There is a huge hole in this story. There are no protocols for naming things. We have to invent ad hoc ways of naming things. Mass delusion [illusion].
Brian McBride: I think you overstate your case. The names are not an illusion, but the binding between the object and the name.
Tim Berners-Lee in IRC: Indeed one names thinhe alluded to an illusion but was deluded. Pat alluded to an illusion but was deluded.
Jeremy Carroll (Hewlett-Packard): [missing comment]
Noah Mendelsohn: In principle it is nice to have a truly uniform naming system. Then you get to the fact of the engineering matter.
Roy Fielding: Things are coming together vs. falling apart.
Steven in IRC: For the record: I have nothing against URIs, nor against typing them
David Orchard (BEA): What different constraints than REST are being applied? Should W3C, in particular TAG, be in the business of documenting one set of constraints? Or describing overlap?
Norm Walsh in IRC: SOAs?
Henry Thompson in IRC: Service-Oriented Architectures
Noah Mendelsohn: I would appreciate from the TAG some clarity. I do not believe everything has to be RESTful. I would like to see the TAG weigh in on this. Looking at scenarios of streaming video, etc., REST is good. I'd like to have URIs for the P2P resources, but they involve an engineering architecture that's not obviously like HTTP.
Dan Connolly in IRC: p2p is tricky... it's clearly too important to ignore, but I haven't found time to play with it enough to answer the questions Noah just riffed about.
Roy Fielding: The goal of REST is not to tell folks the extent of the web. If there are aspects of REST that don't fulfill Web services, that's ok. But you have to go back and decide [missing comment].
Moderator: Ian Jacobs (W3C). Panelists: Tim Berners-Lee (W3C), Steve Bratt (W3C)
Ian Jacobs: Let's do breathing exercises.
[slide: Is the Integer 1 a Resource?]
RylaDog in IRC: not true
Micah Dubinko in IRC: http://www.iso.ch/integers/1
Norm Walsh in IRC: No, mdubinko, that's 404 not 1 :-)
[Ian Jacobs proposed various topics]
Henry Thompson (W3C): About 15 people had a BOF on Linking.
Steven in IRC: 20 more like
Henry Thompson: The Linking WG expired at end of 2002. There are structural and technical issues on moving forward about talking about links. The BOF agreed about some procedural issues. This will be sent to some list soon. The AB is dealing with normative errata. I think they've (finally) done a good job. The new version of XML Schema is trying out this new process.
PStickler in IRC: val:(http://www.w3.org/2001/XMLSchema%23integer)1 (c.f. http://sw.nokia.com/metia/infrastructure/draft-pstickler-val-00.html)
Frank McCabe (Fujitsu): BOF on Semantic Web Services. About 20 people. Topics: What is meant by SW Services, and what to do about them. Thinking of starting an IG. There will be a mailing list [scribe didn't get the name]. The semantic web also requires services, such as ontology services. There is a class of services which have publicly understood semantics. Encourage people to participate.
PStickler in IRC: "1"^^<http://www.w3.org/2001/XMLSchema#integer> denotes the integer 1, and RDF says it's a resource ;-)
Dan Connolly in IRC: PStickler, I'd expect to find compare/contrast with data: in draft-pstickler-val. I don't see any.
Dan Connolly in IRC: [list name www-ws, perhaps?]
Martin Dürst (W3C): Report on BOF on Gaiji: Glyph variants and unencoded characters. w3c-char-glyph [Member-only link].
Michael Sperberg-McQueen (W3C) in IRC: Gaiji not the same as glyph variants.
RylaDog in IRC: Kanji?
Tim Berners-Lee in IRC: LX ?
David Marston (IBM): XSLT and Xpath conformance testing BOF. In coordination with OASIS we're ready to show the test organization to the world. Will be a good example of the QAWG test guidelines.
Michael Sperberg-McQueen in IRC: Kanji which are new / unconventional / new variants of existing glyphs (so glyph variants aren't irrelevant)
Martin Dürst in IRC: gaiji subsumes glyph variants and non-encoded characters but you could say that gaiji is a particular solution for these issues.
Paul Cotton: As a TAG member, I notice only a few people on www-tag list. When mixed namespace docs were being discussed, it was pointed out as an important problem. How are we going to get those people engaged (if they aren't on the list). I'd like to hear suggestions from the audience how the TAG is supposed to learn their views on the issues. Should the TAG have some other mechanism to garner input?
Dan Connolly in IRC: list per issue... ping has a tool that implemented that cheaply... nosylists or some such...
Paul Grosso in IRC: The TAG should put a special filter on www-tag that doesn't accept any more than 2 postings per day by the same person.
Tim Berners-Lee: The guy who asked this question caught me at coffee break. There are some people who expected it to be solved in another context...[missing comment]. The Tech plenary is a good place to bring these things up. The TAG doesn't solve all the problems, we try to pass them off.
RylaDog in IRC: Processing something...
Martin Dürst in IRC: PGrosso++! (except for the TAG members, of course)
Ralph Swick in IRC: PGrosso++
PStickler in IRC: The key difference between val: and data: is that data: would force all datatypes to be defined as content types whereas val: URIs are just RDF typed literals in URI form.
Janet Daly: Paul Grosso on IRC suggests limiting the number of posts per day on www-tag.
Dan Connolly in IRC: PStickler, pls say that in your draft.
Arnaud Le Hors: I don't think that your care of the importance of a problem implies you want to work on solving it.
PStickler in IRC: The draft has expired. I guess I should re-publish it, with inclusion of the comparison with data:
Jacek Kopecky: Outside of AC meetings, the TAG list is OK, but in the AC meeting a bit of advertisement for the TAG issues would be helpful. We heard of three issues, we might have heard in less detail of more issues, and maybe early in the morning.
Al Gilman: Once an issue is accepted, the topic should be moved to a list which is archived, but not distributed.
Norm Walsh in IRC: Not a list, but a wiki or other web forum thing.
Dan Connolly in IRC: (I tried launching a TAG wiki early on. it died due a combination of technical and social factors)
Harvey Bingham: I'm concerned that working within WAI, we've been successful with outreach [missing comment].
Eric Prud'hommeaux (W3C): Report on RDF-Query and RuleML BOF... We had the longest running BOF. We talked a lot about abstractions, etc, etc,. We started coming up with a model. The problem is that there are RDF recommendations, but now how do you use it? Lots of query languages and protocols. Where is the commonality.
Susan Lesch (W3C): Report on markup language tokens BOF. Three or four people were able to articulate the problem. We covered classes, SVG's impeccable markup, links. We came up 3 or 4 projects: Help for new/all editors. Document production tools.
Steven Pemberton: RDF... Who wants to write or read that stuff?
[applause]
Dan Connolly in IRC: RDF Query and Rule languages Use Cases and Examples survey
Tim Berners-Lee: There are a lot of use cases for RDF queries. But they're not in XML, which is why they're easy.
Jacek Kopecky in IRC: Maybe the TAG could use bugzilla for issue tracking? (Bugzilla was suggested in the WS-Desc WG)
Dan Connolly in IRC: query part of semweb arch meeting
Karl Dubost (W3C) in IRC: The first time I tried the RDFLib Python libraries, the lightbulb finally flashed on.
libby in IRC: alberto and andy;'s document
Al Gilman: XAG makes radical claim is that the most useful doc is one readable both by people and machines. We have in "accessibility" some information which some users will process and others won't. There's a strong appeal that you have and document a model. There's not good documentation of what works and doesn't work. Speculate we want to do lots of prototyping in RDF along the way [missing comment].
Brian McBride: There was an occasion some months ago that Ian Horowitz said "no one can write this stuff (RDF-XML)". I did it in the back of the room. RDF is very elegant. Don't confuse it with the XML syntax.
Roger Cutler: Al Gilman said "the core of the web is interaction between an individual and a machine." I think that's the Web of yesterday. The new metaphor is business to business interaction. The W3C is not in the leadership position. I think it's OASIS.
Pat Hayes: The DAML is encoded in RDF-XML. There are 6 million lines of code. Who wants to write HTML? Who wants to write XML? We do it because it's useful.
Håkon Wium Lie: Lots of people are using Emacs. HTML can be written beautifully. I think a goal for W3C would be to reuse elements and attributes without using namespaces.
Ian Jacobs: Tantek suggested there be a W3C namespace.
Tim Berners-Lee: I think it's a perfectly reasonable idea. Just propose a Working Group.
Steve Bratt: Let's applaud Ian. Attendees please fill out the plenary survey [Member-only link].
To audience applause, Steve Bratt thanked the organizers (Amy van der Hiel, Susan Westhaver, Marisol Diaz, Josh Friel, Saeko Takeuchi), the Systems Team, the scribes (Marie-Claire Forgue, Henry Thompson, Ian Jacobs, Ivan Herman, Dean Jackson, Simon Hernandez, Alan Kotok), and the program committee (Paul Cotton, Debbie Dahl, Janet Daly, Donald Eastlake, Al Gilman, Patrick Ion, Brian McBride, Noah Mendelsohn, David Orchard, Steven Pemberton, Steve Bratt).
Amy van der Hiel (W3C): Thanks to Ralph!
Adjourned at 18:13 ET
{kind=link}
{kind=link}