HTML 5, one vocabulary, two serializations
Author(s) and publish date
- By:
-
-
Karl Dubost
-
- Published:
It seems not very clear for many people. So let's set the record straight. HTML 5 can be written in html and XML.
HTML 5 specification is the description of a vocabulary that you can write in two different syntaxes (html and XML) depending on your developer needs, markets and applications. The precedent versions of the HTML vocabulary (HTML+, HTML 2.0, HTML 3.2) were written using SGML syntax rules. HTML 4 had already two syntaxes: SGML (called HTML 4.01) and XML (called XHTML 1.0).
HTML 5 is being written in two syntaxes: html and XML. Because SGML has never been deployed in browsers and many html authoring tools, HTML 5 defines a new serialization called html, which looks a lot like the previous known SGML.
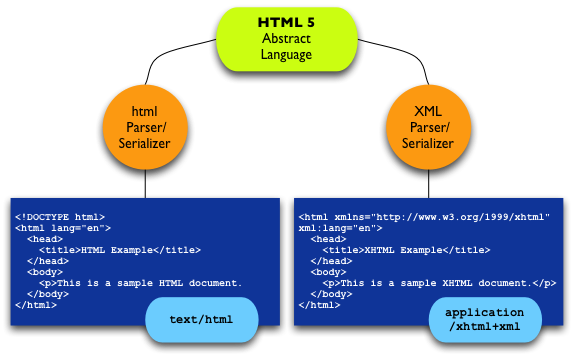
kudos to James Graham for the graphics idea.
I usually do not like that kind of visualisation. But that graphic really did convey the message elegantly and efficiently! Kudos for good presentation.
I think the confusion arises when you add XHTML 2.0 to the mix. And what would the picture look like if you added HTML+, HTML 2.0, HTML 3.2, HTML 4, HTML 4.01, XHTML 1.0, XHTML 2.0 and what not? Very confusing.
Oooohh prettiness :)
For strict accuracy, the arrows on each parser/serializer branch should probably go in both directions, but I'm not sure it matters much.
Excellent! Hopefully this visual helps to clear up some of the confusion. Like Simon though I think the issue is what happens when we consider XHTML 2.0.
Thanks everyone.
Why confusing for XHTML 2.0? It's another language which has for ancestor HTML 4 too and which uses an XML serialization, and probably schemas technology. I might create a table to clarify the different assets of each language. Docbook is also another language which helps to describe content and is serialized as XML.
Hi James,
With reference to Quality Assurance Standards. Could you please point me in the right direction on W3, or are we reaching the point where we can validate a standard in grammar and content. Can we? or have we a framework in place to display a Quality Assurance Marque. Where development responsibility has been demonstrated in HTML, CSS etc.
I welcome your esteemed advice and guidance.
Respectfully Yours
Alastair Agutter
Senior WWW Developer and Founder
Riverside Networks Computer Sciences Academy
the illustration must indeed be impressive from the feedback so far, but i wouldn't know, as there is no long description of the graphic, only the uninformative terse descriptor (a.k.a. alternative text) "HTML5 Serializations"
why is this? is the graphic too complex for a textual description? it is obviously intended to provide an "ah-hah!" eureka moment for those confused by the issue of serialization as it pertains to HTML5, but there is no equivalent "ah-hah" mechanism for those who cannot process the graphic used as the main content of this page.
is this a shortcoming of the blog interface (an inability to associate a long descriptor for the graphic) or is it due to simple carelessness? either way, it is an inexcusable violation of the Web Content Accessibility Guidelines, versions 1 and 2, W3C Technical Recommendations upon which W3C web space has a well-defined dependency; if the W3C doesn't follow the Web Content Accessibility Guidelines, how can the W3C expect others to adhere to them? this violation is particularly distressing as the perceptual black hole it creates appears on the W3C's own Quality Assurance blog...
no, this post is not "spot-on topic", but the issue it outlines is an important one -- i'm not asking for the proverbial thousand words which a picture is held to be worth, but at least for a description of that which others are praising -- even those who usually do not like that kind of visualisation
and as for the versioning question, HTML 4.01 was serialized as XHTML 1.0, not XHTML4 -- therefore, HTML5 should be serialized not as XHTML5, but as XHTML 1.5
Hi gregory,
I will try to improve the graphics, you will tell me what it gives for you. and if it's more understandble. Note that I have not talked at all about XHTML 5. I'm just saying that there are two serializations of the same language HTML 5. One which is html and one which is XML.
I think it would be inappropriate to call the XML variety of HTML 5 "XHTML 5"
What makes more sense to me is that just as HTML 4's XML variety is "XHTML 1.0" (and everyone accepts that the numbers are obviously different), so (given that there is already an "XHTML 1.1) calling it XHTML 1.5 would make the most sense. And when there is an HTML 6 someday in the future its XML equivalent would be "XHTML 1.6" and so on.
Otherwise, as XHTML advances, it could get confusing: XHTML 3 - OK, 4 - OK, 5 - Oops! We already have an "XHTML 5" so what do we do now?
It would be very nice, in the rush to build a rich environment into HTML, if the developers would let the users (not all of whom have great bandwidth) request HTML 3.0 or HTML 1.0 as part of the HTTP:// call so that they could get the content in a more timely manner and with a minimum of angst over questions like "Do I really have to install yet another 'plug in'?". The great flash and sizzle that many of these plug-ins represent are often just Hollywood-style fluff that annoys people who need content.
The following table may help people who do not understand all the meaning of "HTML 5, one vocabulary, two serializations" (read in fixed-lenght font)
text/html | application/xhtml+xml
----------|----------------------
HTML 2.0 |
HTML 3.2 |
HTML 4.01 | XHTML 1.0
| XHTML 2
HTML 5 | HTML 5
The following table may help people who do not understand all the meaning and consequences of "HTML 5, one vocabulary, two serializations"
Yes, this graphic is colorful and demonstrates the dual-nature of HTML 5. I think it's also helpful to see a visual overview of the various markup languages and their relation to each other. See my March 2007 blog posting with a chart that includes HTML, XHTML, XML, etc. .
Edit: I have fixed your link. Karl.
Damn it i don't like this..
I mean on one side you have serialize to pure untainted XML...
on the other side you have serialize to dog turd (HTML/SGML)
Who's bright idea was it to bring back the dark ages of SGML?
We where moving into the blessed enlightenment of XML and then this happens!!!
WHY?!
What possible reason can there be for bring back this taint?!
I mean seriously what the hell is wrong with strict XHTML?!
I was looking forward to XHTML 2.0 not this crap!
This whole project strikes me as the worst possible idea anyone could possibly have had!
I mean its like auguring that we should "teach the controversy" (for those familiar with how creationism tries to sneak into the American school system).
IMHO (for every sentence):
XML is a subset of SGML. SGML includes all markup languages. "XML serialization" just adds a few syntax rules to SGML. The mistaken distinction here arises from XML parsers failing and tag soup being continually supported.
I personally see no problem with a web page failing when a tag doesn't have the proper syntax, just like in ANY OTHER programming language. Sure it would break a lot of the web, but a lot of the web NEEDS to be updated as well.
If it were my job to create an image as the article shows (great image, btw), I would make a Venn diagram with SGML as a large circle, XML and HTML 4 as circles inside the SGML circle, with the XML+HTML overlap as XHTML. HTML 5 on the other hand is just another circle inside the SGML circle that overlaps HTML4 and XML. This new HTML 5 circle doesn't help simplify markup, but just stands as a replacement to HTML 4, as in the future the HTML 4 circle will fade away, leaving us with what we had before we had HTML 5.
Again, just my opinion though.
@zerq
What about this valid HTML 5 document?
@zerq
As far as I understand it (and beware confusion/misunderstandings on my part), the relevant ideas behind HTML5, expressed in your terminology, are that:
You can be "moving into the blessed enlightenment of XML" (heh) if you like - and please encourage others to join you. Hence the existence of the XML serialisation of HTML5. The WHATWG are not attempting to delay the arrival of XML Nirvana.
The WHATWG are not trying to "bring back this taint" - rather, the tag soup never went away, neither in the content nor in the parsers in browsers, and as far as anyone can tell, is here to stay for reasons of backward compatibility, broken authoring tools and (more generally) humans being prone to error. Any proposal to 'break a lot of the web' (a la @Anton) is a non-starter. People would avoid any browser or other software that worked this way. My mum doesn't care whether the web pages she uses are valid or not - she cares that they work right now, and the WHATWG want them to continue to work.
What 'is wrong with strict XHTML' is that failure to get such content right, accompanied by so-called 'draconian' error handling in XML parsers in browsers yields a poor end-user experience with little to no graceful degradation.
Invalid content is arguably 'the worst possible idea anyone could possibly have had'. But it's not the WHATWG's idea - it's a fact on the web. So browsers must be forgiving to work around this. The WHATWG are describing what browsers actually do, not proscribing what they should do.