Since its first release, in May 1996 Jigsaw has undergone major changes. Most of these changes are evolutions toward making it a devlopment environment for writing servers, while previously it was targetted at providing a sample implementation of an HTTP server. As a devlopment toolbox, Jigsaw aims at providing a suite of modules that covers the various needs of server's implementors. These modules are often defined as a set of Java interfaces that integrate with and rely on - as much as possible - with the standard Java librairies.
This document covers the two central pieces of the puzzle: the w3c.jigsaw.daemon module and the w3c.jigsaw.resource module. We do not intend to provide here a programmer's guide, nor a specification, but plain old text to explain things. The interested reader can consult:
The Jigsaw daemon module (api, specifications) goal is to provide a homogeneous interface for any server running within a single Java virtual machine. The three main functionalities this module provides are:
On the other hand, carefull design of that single interface is required in order to ensure the following properties:
Since release 1.0alpha5, one new way of running Jigsaw is through the ServerHandlerManager class. This class manages a set of ServerHandler instances; once all these server handlers are started, the daemon is ready. The following picture shows the relationships between server handler instances and the server handler manager:
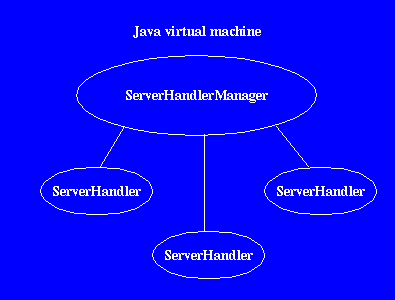 |
A sample usage of that architecture may be to have, say a public http server handler listening on port 80 of the host along with a public http proxy, running on port 8001. An AdminServer instance would also probably listen on a given port to handle remote configuration of these two servers, and for extreme fun, you can imagine that VM also handling a multicast receiver to feed the http proxy.
The rest of this section decribes:
For more detailed informations, the reader should consult either the API documentation or the specifications.
A typical scenario is to launch, within a Java VM - one instance of the ServerHandlerManager class through the command line, and have that instance initialize all the server handlers. The basic mechanism for the server handler manager to initialize the server handler instances, is to read a property file that describes the servers to be run, along with their classes. Here is a sample of that property file:
w3c.jigsaw.daemon.handlers=http-server|admin-server|mux-server http-server.w3c.jigsaw.daemon.class=w3c.jigsaw.http.httpd mux-server.w3c.jigsaw.daemon.clones=http-server admin-server.w3c.jigsaw.daemon.class=w3c.jigsaw.admin.AdminServer
When the server handler manager reads that property file, it first looks
for the w3c.jigsaw.daemon.handlers property value. That property
provides a | separated list of server handler identifiers. For each identifier,
it looks for either an
identifier.w3c.jigsaw.daemon.class or an
identifier.w3c.jigsaw.clones property. If the first one
is found (ie a class), the server handler manager instantiate it and calls
its
initialize
method, providing as parameters a pointer to itself, the identifier for the
server and a set of properties from which the server handler should initialize
itself. If a clones property is set instead, the server handler manager will
look for an already created server handler instance of that name, if found,
it will clone it to create the new server handler instance.
The above sample property file, for example, will start by initializing a
w3c.jigsaw.http.httpd server handler instance, and will then
clone it to create the admin-server instance. The properties specific
to each of these server handler are read from (resp) http-server.props
and admin-server.props.
As was shown in the previous section, the first thing you get by implementing the ServerHandler interface, is a homogeneous way of launching server handlers within the same Java VM; but that's not the end of it. This section tries to provide a brief idea of the other functionalities you get, by discussing the ServerHandler interface.
The first set of methods provide basic admin functionalities:
public void initialize(ServerHandlerManager shm
, String id
, ObservableProperties props)
throws ServerHandlerInitException;
public ServerHandler clone(ServerHandlerManager shm
, String identifier
, ObservableProperties props)
throws ServerHandlerInitException;
public void shutdown();
The first two methods where described above. The first one is called when creating a ServerHandler instance "from scratch", while the second is called when creating one by cloning another one. Both methods can throw a ServerHandlerInitException if the server handler couldn't be launched properly. Of interest here, the fact that the ServerHandler is provided not with a java.util.Properties, but rather with a w3c.util.ObservableProperties whose changes can be monitord (to allow server handler instances to dynamically react to changes to properties).
The shutdown method is used by the ResourceHandlerManager to stop a given server properly.
A second set of methods is made of a set of accessor methods, to access various pieces of the server handler:
public String getIdentifier();
To access the server handler identifier within the current Java VM.
public InetAddress getInetAddress();
To access the INET address on which that server is listening for connections. Note again, that this address need not be the address of a TCP stream, it can really be anything ranging from a UDP address to a multicast address.
The third set of methods provides basic (and common) logging facilities:
public void errlog(String msg) ;
To report an error within that server handler context.
public void log(String msg) ;
To log a normal transaction within that handler context.
public void trace(String msg);
To emit a trace within that server context.
Finally, one of the most important method is the one that allow homogeneous access to the server handler configuration:
public w3c.jigsaw.resources.ContainerInterface getConfigResource();
This method is responsible for returning a resource that the caller can use to both:
Let's get into more details.
As was stated in the introduction of that section, one of our primary goal for defining that interface was to provide a homogeneous customization framework for server handlers. The way we acheive this is through the usage of resources.
As we will see in next section, the two fundamental properties of resources are:
The main feature we use here is the self-descrptive nature of resources. Without getting into too much details, the important point here is to note that for all of its attribute, a resource can provide enough information for an editor to popup the right dialog to edit values of that attribute.
By describing the server handler configuration through resources, we make sure we draw a nice line between the graphical configuration front end, and the server handler internals. As a side effect, we can reuse for free existing resource editors to handle that configuration.
Since Jigsaw 1.0alpha5, the resource module has been isolated, and is available as a standalone Java package in w3c.tools.store. That module basically implements an efficient self-describing object model within the Java language. That model assumes that an object - or AttributeHolder - is made of a set of attribute values.
By using this meta-description mechanism, attribute holders can be made persistent, to do so the object is subscribed to a resource store whose role is to maintain that object persistent; the base class for persistent attribute holders is the Resource class, which works in conjunction with the ResourceStore interface.
To limit memory usage, a ResourceStoreManager manages the set of loaded store, and keep track of the ones that have not been used recently to unload them dyncamically. For this reason, an object that holds a reference to a resource store must implement the ResourceStoreHolder interface, and an object that holds a reference to a resource must implement the ResourceLocker interface. Overall the picture looks like this:
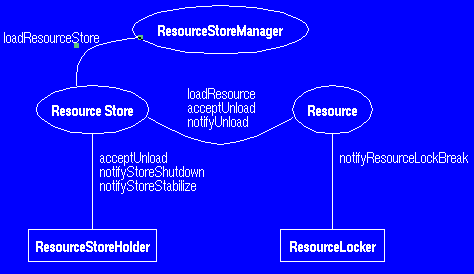 |
Each link in the picture is a 1-to-many: a resource store manager manages several stores, each store can have several holders, and can hold several resources. Each resources can handle multiple lockers. The rest of this section describes:
As implied by their names, the main function of attribute holders is to hold a bunch of attribute values. Each class of attribute holder (ie any subclass of AttributeHolder) register the set of attributes they handle to an AttributeRegistry, typically in a Java static initializer that looks like this:
public MyResource extends Resource {
protected static int ATTR_COUNTER = -1;
static {
Class c = Class.forName("MyResource");
Attribute a = new IntegerAttribute("counter", 0, Attribute.EDITABLE);
ATTR_COUNTER = AttributeRegistry.registerAttribute(c, a);
}
...
}
This piece of code creates an instance of the IntegerAttribute class whose role is to describe the counter attribute. By registering that attribute to the attribute registry, the class gets back some integer that should be thought of as an opaq token to access the attribute.
For all sub-classes of AttributeHolder, the attribute registry maintains
the total list of both inherited and proper attributes; given any sub-class
of AttributeHolder, this registry knows the exact list of attribute it supports.
For example, the above MyResource class will inherit from the
Resource class the identifier and resource-store attributes
(respectively the key of the resource within its store, and a pointer to
its resource store).
The Attribute class is used for three purposes:
Attribute.EDITABLE flag means that that attribute is editable
by a human operator).
By considering an attribute holder as a set of attribute values, we also allow for easy monitoring of attribute value changes: all access to attributes are ultimately processed through either:
public void setValue(int idx, Object value);
in case of a write access, or:
public Object getValue(int idx, Object def);
in case of a read access. By overriding these methods, an instance of
AttributeHolder can monitor all accesses and react consequently. For example,
if MyResource class is to monitor any setting of its
counter attribute, it would redefine setValue as:
public class MyResource ... {
public void setValue(int idx, Object value) {
super.setValue(idx, value);
// Handle counter setting:
if ( idx == ATTR_COUNTER ) {
// The counter has changed perform some action:
...
}
}
}
The Resource class augment AttributeHolder functionnalities with minimal persistency support. An AttributeHolder knows how to pickle/unpickle itself, a Resource - by working in conjunction with a resource store - knows how, when and where to save itself.
The basic idea here, is that to make an AttributeHolder persistent, you just plug it into a ResourceStore compatible instance (independant of its underlying implementation). The special identifier attribute of any Resource instance is used as the key, within a resource store of that object. Basically, to create a resource instance, you would use something like:
Resource myresource = new SomeResourceClass();
Hashtable defattributes = new Hashtable(11);
defattributes.put("identifier", "myresource");
myresource.initialize(defattributes);
Once this code has been run through, myresource points to an initialized instance of a resource (note depending on the actual class of the Resource, you may need to provide more or less default attribute values). Once the resource is created, you can plug it into a resource store:
ResourceStore store = ...; store.addResource(myresource);
To restore that resource (even if the JavaVM has been restarted in the meantime), one can then use:
Resource myresource = (Resource) store.loadResource("myresource");
Note that the ResourceStore interface doesn't make any assumption on the technology used to actually save the pickled version of resources to stable storage. In fact, the current Jigsaw release comes with two implementation of that interface:
We have made our best efforts to ensure that this interface would be implementable on top of any existing database technology, and we do plan to provide such an implementation.
As we want to allow a single application to handle several thousands of resources, and as we don't want memory requirements to grow proportionally to that number, an other object, the ResourceStoreManager, is introduced to keep track of loaded resource stores. The idea is that by keeping only a constant number of resource stores in memory, we can limit memory consumption of the underlying Java VM. The ResourceStoreManager is that application-wide object that keeps a list of recently used resource stores, to unload - when needed to keep the count constant - least recently used stores if a new store is to be loaded.
Beside that mechanism, resource store implementors are free to use their own caching scheme within their own resource store. As an example, the jdbmResourceStore itself keeps a cache of the resources it loads from its store (keeping only a constant number of resources loaded at any time).
Jigsaw Team
$Id: architecture-new.html,v 1.6 1997/07/31 11:00:29 abaird Exp $